 >
> FAIR Data Principles: Benefits, Challenges & FAQs

FAIR Data Principles in Life Sciences Data Management: Key Takeaways
- FAIR data principles offer a structured approach to organizing and sharing data
- Benefits of FAIR data in life sciences data management include enhanced data quality and research data integrity, improved reproducibility, and greater long-term data usability
- Obstacles to adopting FAIR data principles include outdated, disconnected systems and inconsistent metadata standards with poorly aligned terminologies
Life sciences organizations are generating massive volumes of experimental, clinical, and observational data, but how much of it is usable?
Can your teams efficiently locate and trust existing datasets, or are they stuck recreating results from scratch?
This makes the FAIR data principles a proven framework for maximizing the long-term value of scientific data.
In this guide, we will:
- Explore the key benefits FAIR delivers to pharmaceutical and life sciences organizations
- Discover the strategic and technical challenges that often arise during implementation
- Share answers to common questions for teams aiming to become FAIR-compliant
Explore Our LIMS Consolidation Solution.

Understanding FAIR Data Principles
The FAIR data principles, short for findable, accessible, interoperable, and reusable, provide a framework for structuring and sharing data to unlock its full value.
These principles aim to make data easily discoverable, accessible, and reusable by humans and machines.
1. Findable
Effective reuse starts with making data easily discoverable.
This requires using rich, machine-readable metadata, assigning standard identifiers like DOIs, and registering datasets in searchable repositories.
These practices are foundational to the FAIRification process, enabling automated discovery and supporting broader accessibility and reuse.
2. Accessible
Data should be accessible to authorized users, and metadata must remain retrievable through standardized protocols using unique identifiers, even if the data itself is no longer available.
Once users locate the data, they should clearly understand how to access it, including any required authentication or authorization steps.
3. Interoperable
To support effective integration and analysis, researchers must structure data and metadata using standardized formats, shared vocabularies, and formal ontologies.
These practices ensure systems can interpret the data consistently, allowing users to combine datasets and apply them across diverse tools, workflows, and platforms without losing meaning.
4. Reusable
FAIR aims to maximize data value through reuse. Achieving this requires data stewards to provide rich metadata, traceable provenance, and clear usage of licenses.
These practices enable confident replication and integration while preserving research data integrity across diverse applications.
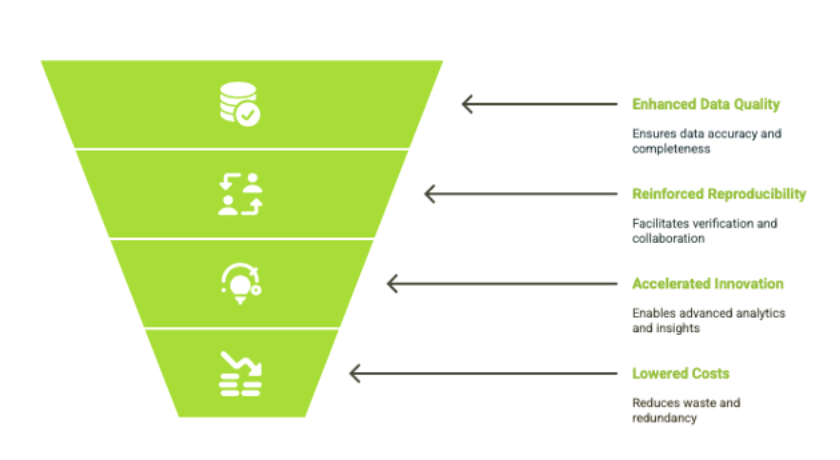
Key Benefits of FAIR Data in Scientific Research
These data principles offer a structured approach to life sciences data management by enabling more efficient, accurate, and scalable ways to organize, share, and reuse scientific information.
1. Enhanced Research Data Integrity and Quality
Adhering to these principles ensures that data is:
- Described with metadata
- Stored in structured formats
- Managed through standardized practices
These elements improve data integrity by minimizing inconsistencies and enabling automated quality checks.
As a result, researchers can trust that datasets are complete, accurate, and contextually meaningful.
2. Reinforced Reproducibility and Collaboration
Researchers in biomedical and pharmaceutical fields often struggle to reproduce published results.
FAIR principles help address this by:
- Ensuring traceability of data workflows and changes
- Clarifying provenance, including who generated the data and how
- Applying standardized annotations to enhance clarity and consistency
These practices support internal replication and enable external collaborators and regulators to independently verify results, an essential requirement in preclinical and clinical development.
3. Accelerated Innovation and Discovery
By ensuring data is machine-readable and interoperable, FAIR principles make it easier to integrate information across different systems and research domains.
This unified data environment enables advanced analytics, supporting:
- AI-driven identification of new therapeutic targets
- Detection of biomarker patterns across datasets
- Streamlined clinical trial design and optimization
4. Lowered Costs and Reduced Waste
FAIR principles reduce costs by eliminating data redundancy, streamlining access, and enabling reuse of validated datasets.
Instead of repeating experiments or reconducting assays due to inaccessible or poorly documented data, researchers can easily locate and apply existing results.

Challenges in Implementing FAIR Data Principles
Implementing these data principles offers long-term value but presents several practical and strategic challenges that organizations must address, including:
1. Fragmented Legacy Infrastructure
A benchmark study revealed that:
- 56% of respondents identified a lack of data standardization
- 44% cited limited resources
- 41% pointed to unclear data ownership
These challenges are especially evident in scientific organizations, where fragmented IT ecosystems, spanning multiple LIMS, ELNs, proprietary databases, and file systems, remain the norm.
Legacy tools in these environments often lack semantic interoperability and lock data into inaccessible formats, hindering automated integration, delaying analytics, and limiting long-term usability.
Strategic implication: Without central harmonization, cross-study insights and advanced modeling (e.g., artificial intelligence and machine learning) remain out of reach, undermining data monetization and innovation potential.
2. Non-Standard Metadata and Vocabulary Misalignment
Inconsistent metadata remains a major barrier to FAIR, as many labs still use free-text entries, custom labels, and non-standard terminology.
Without adherence to shared ontologies and vocabularies (for example, ASM (Allotrope Simple Model), machine-actionable reuse is infeasible.
Strategic implication: Data becomes locked in its original context, making it unsearchable, non-integrable, and incompatible with regulatory traceability or third-party validation.
3. Lack of Scalable FAIRification Tools
Manual curation of datasets, like assigning persistent identifiers, mapping to ontologies, and tagging with provenance, doesn’t scale.
Yet many organizations lack:
- Automated FAIRification pipelines
- Integration layers that translate native lab outputs into standardized, FAIR-compliant formats
Strategic implication: Teams fall short not due to unwillingness, but due to tooling gaps.
4. Ambiguous Data Ownership and Governance Gaps
Cross-functional R&D often spans departments, vendors, and external partners.
Without clear governance, it’s unclear who defines metadata rules, assigns access controls, or validates data quality.
In regulated sectors, this ambiguity creates compliance and audit risks.
Strategic implication: FAIR without governance invites inconsistency. Data quality, access, and audit-readiness must be embedded in enterprise-wide data stewardship policies.
5. Insufficient Planning for Long-Term Data Stewardship
FAIR isn’t a one-time project. It demands long-term planning for data archiving, versioning, re-validation, and access continuity.
Without dedicated roles or sustainable processes, initial gains will erode over time.
Strategic implication: FAIR should be embedded into digital lab transformation roadmaps with roles like data stewards, lifecycle owners, and continuous audit frameworks.
6. High Initial Costs Without Clear ROI Models
Implementing these principles requires upfront investment in semantic tools, integration of middleware, cloud platforms, and training.
When value is intangible, such as “future reusability” or “regulatory readiness”, stakeholders may hesitate to fund it.
Strategic implication: Demonstrating FAIR ROI through case studies (for instance, reduced assay duplication, faster submissions, and AI-readiness) is key to sustaining momentum.
How ZONTAL’s LIMS Consolidation Supports FAIR Principles
Transform fragmented laboratory data into a unified, standardized, and machine-actionable format with our LIMS Consolidation platform.
By eliminating the hassle of managing various LIMS data sets, our centralized platform streamlines operations, harmonizes diverse data structures, removes the need for manual consolidation, and reduces potential disruptions.
Here’s how we support and simplify FAIR:
1. Findable
By consolidating multiple LIMS into a centralized platform, ZONTAL ensures that all laboratory data is cataloged and searchable.
This enables easier data discovery through unified metadata standards and indexing.
2. Accessible
ZONTAL maintains secure, role-based access across previously siloed LIMS data.
Even as systems evolve or are phased out, the platform preserves access to historical datasets, critical for long-term accessibility.
3. Interoperable
The platform harmonizes data from different LIMS formats, making it machine-readable and compliant with standardized vocabularies.
This cross-system compatibility allows integrated data to feed into broader research and analytics pipelines.
4. Reusable
ZONTAL’s structured consolidation ensures that historical and active LIMS data are documented with proper context, provenance, and usage rights, supporting reproducibility, audits, and future research reuse.
ZONTAL offers continuous support and customized training to help your team get the most out of our LIMS Consolidation solution.
From initial setup to long-term optimization, we’re here to partner with you at every step, ensuring seamless integration and sustained performance.
Ready to operationalize FAIR data?
FAIR Data Principles: FAQs
Who do the FAIR data principles matter in life sciences?
In life sciences, applying these data principles:
- Improves data quality
- Supports regulatory compliance efforts, including alignment with standards such as GLP, GMP, and FDA data integrity guidelines
- Enables AI-driven analytics, accelerating discovery and reducing duplication of effort.
Is FAIR data the same as open data?
No. This type of data isn’t necessarily open.
While both aim to enhance usability, FAIR focuses on making data usable by both humans and machines, even under access restrictions.
For example, sensitive clinical data can be FAIR if access protocols and metadata are well-defined, even if the dataset itself is restricted.
What does it take to make data FAIR compliant?
FAIR compliance requires more than good file naming.
It involves:
- Assigning persistent identifiers (like DOIs)
- Enriching datasets with standardized metadata
- Using common vocabularies and data formats
- Documenting provenance
- Defining access and licensing clearly
How do these data principles support regulatory compliance?
FAIR principles aren’t regulatory frameworks, but they support compliance by improving data transparency, traceability, and structure.
These qualities are essential for meeting GLP, GMP, and FDA expectations, especially in maintaining data integrity, version control, and audit readiness.
Support end-to-end FAIR transformation.


