 >
> LoRA: An Efficient Way to Finetune Giant Language Models
As large language models (LLMs) like GPT-4, Claude 3, or Grok-1 become increasingly capable, there is growing interest in finetuning them for specialized tasks across industries like biotech. However, finetuning these massive models traditionally requires retraining all their millions or billions of parameters, which is computationally expensive and thus limits practical applications.
Enter LoRA (Low-Rank Adaptation) – a technique that drastically reduces the computational requirements for finetuning giant LLMs. Developed by researchers at Microsoft, LoRA works by only updating a small subset of the model’s parameters during finetuning instead of all of them.
How LoRA Works
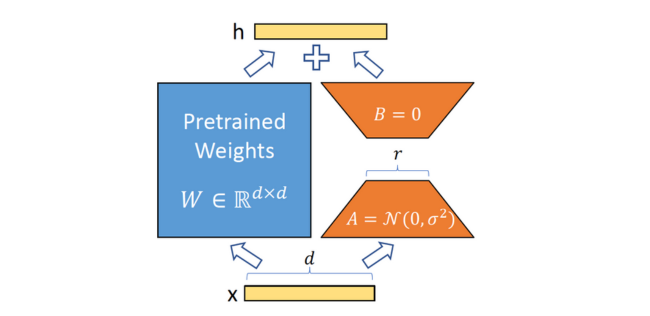
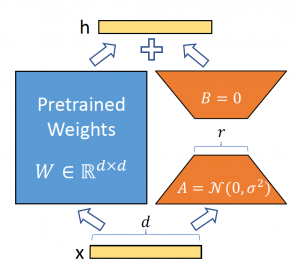
The core idea behind LoRA is to represent the updates to a language model’s weights as a low-rank decomposition instead of fully updating the weight matrices. Specifically, for a pre-trained weight matrix W, LoRA constrains its update ΔW to be a low-rank matrix created by multiplying two smaller rank matrices: ΔW = BA.
During finetuning, only the much smaller matrices B and A are updated, while the original full weight matrix W is kept frozen. This compressed representation of the updates requires far fewer trainable parameters.
At inference time, you can efficiently compute the full weight matrix W + ΔW = W + BA to use the finetuned model without any added latency compared to traditional finetuning.
The Benefits of LoRA
The primary benefit of LoRA is the massive reduction in computational requirements for finetuning, both in terms of memory usage and training time.
In their paper, the Microsoft researchers found that using LoRA reduced the GPU memory required to finetune GPT-3 (175 billion parameters) from 1.2TB down to just 350GB. For storing adapted models, LoRA checkpoints are thousands of times smaller than storing all finetuned weights.
LoRA also provides a 25% speedup during training compared to full finetuning since it avoids calculating gradients for most weights.
Perhaps most importantly, LoRA matches or even exceeds the performance of full finetuning while using orders of magnitude fewer trainable parameters on a variety of natural language tasks.
Enabling New Applications
By drastically reducing the computational cost of finetuning, LoRA opens up new practical applications that were previously infeasible with traditional methods.
For example, biotechnology companies can now finetune giant LLMs as knowledge bases for querying biomedical research, generating protein sequences, or other domain-specific applications. Individual researchers can finetune public LLMs on modest GPU resources.
Since LoRA trained models have such small footprints, it also becomes feasible to store and serve many finetuned versions tailored to different requirements, allowing on-the-fly switching between them.
LoRA in Practice
While still a relatively new technique, LoRA is already seeing significant adoption and successful use cases.
At Microsoft, LoRA has been used to create and deploy finetuned models for querying and analyzing biomedical literature. Anthropic has open-sourced a constitutional AI model called InstructGPT finetuned with LoRA on GPT-3 to behave ethically and truthfully.
Startups like Firefly are using LoRA to create customized AI assistants for enterprises by finetuning open source LLMs. Several AI labs are exploring LoRA for safely deploying large open-source language models without access to the original training data.
As LLMs continue growing, techniques like LoRA that enable efficient finetuning and deployment will likely become ubiquitous across industries looking to harness the power of large language models in a cost-effective manner. The applications enabled by LoRA are just beginning to emerge.
To support these data heavy innovations we have developed our laboratory data preservation which enables you to store you scientific data securely and share it with remote teams. Get in touch and see how we can support your digital lab data management requirements.


