 >
> From Imbalance to Harmony: Empowering Models with Synthetic Data
Who doesn’t care about larger and more balanced training data? While over and under-sampling are established methods to deal with the imbalance issue, Ye-Bin et al. propose an alternative way to overcome imbalances through generative models in a fresh arxiv paper (https://arxiv.org/pdf/2308.00994.pdf).

In the realm of visual tasks, deep neural networks (DNNs) have exhibited impressive performance, heavily reliant on rich and diverse labeled data. However, this advantage falters when dealing with underrepresented classes, leading to diminished DNN performance due to data imbalance. This issue, arising from unequal data distribution, is particularly prevalent when dealing with internet-sourced data characterized by power law cluster size distributions. These imbalances can give rise to biased classifiers, posing ethical concerns and performance challenges. To address this, they proposed a novel approach that utilizes generative models to balance class samples prior to applying task-specific algorithms, differing from traditional techniques that primarily focus on algorithmic remedies. This method leverages pre-trained generative diffusion models on expansive web-scale datasets, offering a departure from limited, bounded datasets. By rectifying class imbalance, it provides a crucial first step in mitigating both class and group imbalance. This approach outperforms counterparts on benchmarks for long-tailed recognition and fairness, while also enhancing classifier robustness.
The proposed method aims to tackle data imbalance problems from a data-driven perspective, employing synthetic data to balance distributions. The authors explore the impact of the original dataset’s distribution and size on model performance. They devise two settings: one that replaces certain class samples entirely with synthetic ones (extreme data imbalance) and another that uniformly substitutes original samples with synthetic ones. These experiments demonstrate that while synthetic data alone isn’t a complete solution, it can aid in balancing imbalanced distributions.
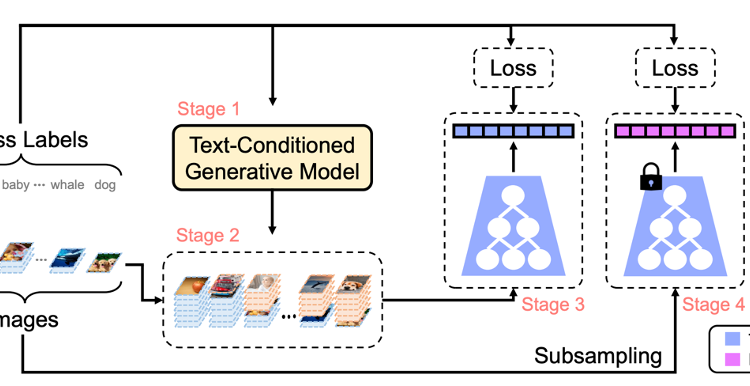
Further, the authors introduce their approach, SYNAuG, which leverages synthetic data to alleviate data imbalances. They target two types of imbalance: class imbalance in long-tailed recognition and group imbalance affecting model fairness. The goal is to achieve balanced data distributions across different tasks. They use generative models, like stable diffusion, to create synthetic data by generating samples with simple prompts. This generated data supplements the original dataset to mitigate imbalances, allowing for uniformized training. The authors further address the domain gap between synthetic and original data by proposing augmentation techniques like Mixup and classifier re-training (see Figure 2).
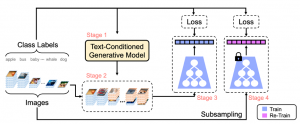
The proposed baseline, SYNAuG, was evaluated in various experiments to assess its performance in addressing data imbalance problems.
Class Imbalance: Long-tailed Recognition
- SYNAuG was evaluated on CIFAR100-LT and ImageNet100-LT datasets with an artificially curated class imbalance.
- Compared to the vanilla Cross Entropy (CE) loss method, SYNAuG exhibited significant improvements across various imbalance factors (IF).
- SYNAuG demonstrated better performance than several prior works, including self-supervised learning, data augmentation, and rebalance classifiers.
- The method’s effectiveness increased when mixup augmentation was applied, particularly for a Few classes.
- Retraining the classifier on uniformized data after Mixup further improved performance.
- Variants of the method explained in Sec. 3.3 was also tested, showing that while they improved upon using only the original data, they were less effective than SYNAuG.
Group Imbalance: Fairness
- The fairness of SYNAuG was evaluated on the UTKFace dataset, considering age, gender, and race labels.
- SYNAuG improved both accuracy and fairness metrics compared to Empirical Risk Minimization (ERM).
- The synthetic data generated without prior knowledge of sensitive attributes still improved fairness, demonstrating the effectiveness of class balancing.
- Integrating Group-DRO, a fairness algorithm, further improved fairness while maintaining accuracy.
- SYNAuG also proved compatible with data augmentation techniques like Mixup and CutMix, as well as deeper network architectures.
Application: Robustness to Spurious Correlation (Sec. 4.3)
- The performance of SYNAuG was assessed on the Waterbirds dataset, focusing on mitigating the effects of spurious correlations.
- Synthetic data generated by SYNAuG consistently improved the performance of the baseline model and DFR (a related approach) in worst and mean accuracy.
- This demonstrated that the generated synthetic data could effectively address the challenges posed by spurious correlations.
- In summary, SYNAuG exhibited strong performance across various experiments, consistently improving both accuracy and fairness in the presence of class imbalance, group imbalance, and spurious correlations. The method’s compatibility with other techniques and its positive impact on different datasets and scenarios further supported its effectiveness.
In conclusion, SYNAuG has shown consistent performance improvements in long-tailed recognition, fairness, and robustness against spurious correlations. While not a complete solution, its simplicity highlights its effectiveness as a foundational baseline. It emphasizes the importance of multi-faceted improvements to address data imbalance challenges.


