 >
> RETNET: Challenging the Inference Cost of Transformer Based Language Models

We all love our new best friend – the large language model. However, this friendship can be a costly one due to the high price of inferences. A novel architecture proposed by Sun et al. holds promise to optimize the return the investment. Retentive Networks (RetNet – https://arxiv.org/pdf/2307.08621.pdf) is a pioneering architecture that combines recurrence and attention to deliver unmatched training parallelism, cost-effective inference, and exceptional performance in large language models. The retention mechanism enables parallel, recurrent, and chunk wise recurrent computation paradigms, making RetNet a strong successor to Transformers for biotech applications. With impressive scalability and efficient deployment, RetNet presents itself as an invaluable tool for the biotech community. Explore the potential of RetNet in revolutionizing AI for biotechnological advancements. Code available at https://aka.ms/retnet.
Large language models typically use Transformers which suffer from inefficient inference and increased GPU memory consumption with growing sequence length. RetNet achieves efficient inference, supports long-sequence modeling with linear complexity, and maintains a competitive level of performance compared to Transformers. The key innovation lies in the multi-scale retention mechanism, which replaces multi-head attention and offers three computation paradigms: parallel, recurrent, and chunk-wise recurrent representations. Extensive experiments demonstrate that RetNet consistently outperforms Transformers and its variants in terms of scaling curves and in-context learning. Notably, RetNet achieves significantly faster decoding along with memory savings during inference, making it a compelling successor to Transformers for large language models.
RetNet is a novel architecture with L identical blocks, each containing a multi-scale retention (MSR) module and a feed-forward network (FFN) module. The MSR module introduces a retention mechanism that combines the advantages of recurrence and parallelism. RetNet offers three computation paradigms: parallel representation for efficient GPU utilization during training, recurrent representation enabling memory-efficient O(1) inference, and chunk wise recurrent representation to accelerate training, especially for long sequences. Extensive experiments demonstrate RetNet’s superior performance, competitive scaling curves, and length-invariant inference cost compared to Transformers.
RetNet incorporates a Gated Multi-Scale Retention mechanism, which operates using different parameter matrices for multiple heads, allowing them to have distinct parameter settings. The model stacks L identical blocks, consisting of a multi-scale retention (MSR) module and a feed-forward network (FFN) module. The MSR module, utilizing parallel, recurrent, and chunk wise recurrent representations, efficiently handles training and inference. Extensive experiments demonstrate RetNet’s superior performance and competitive scaling curves.
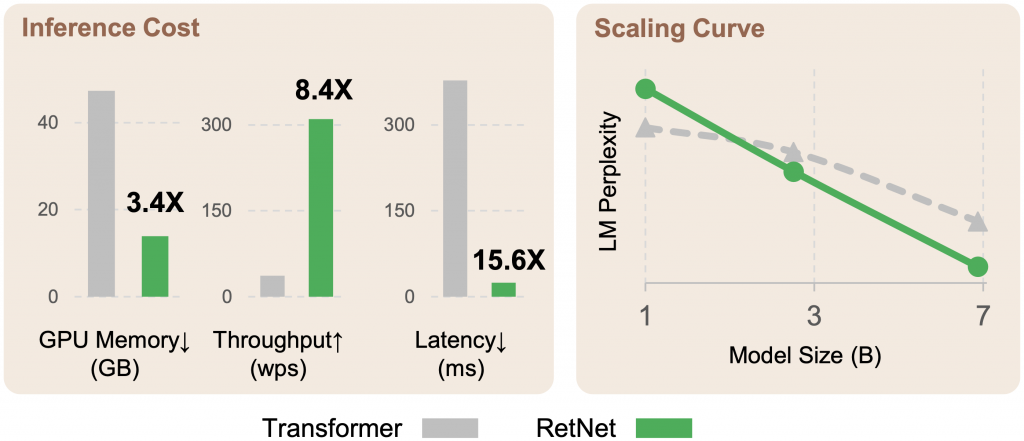
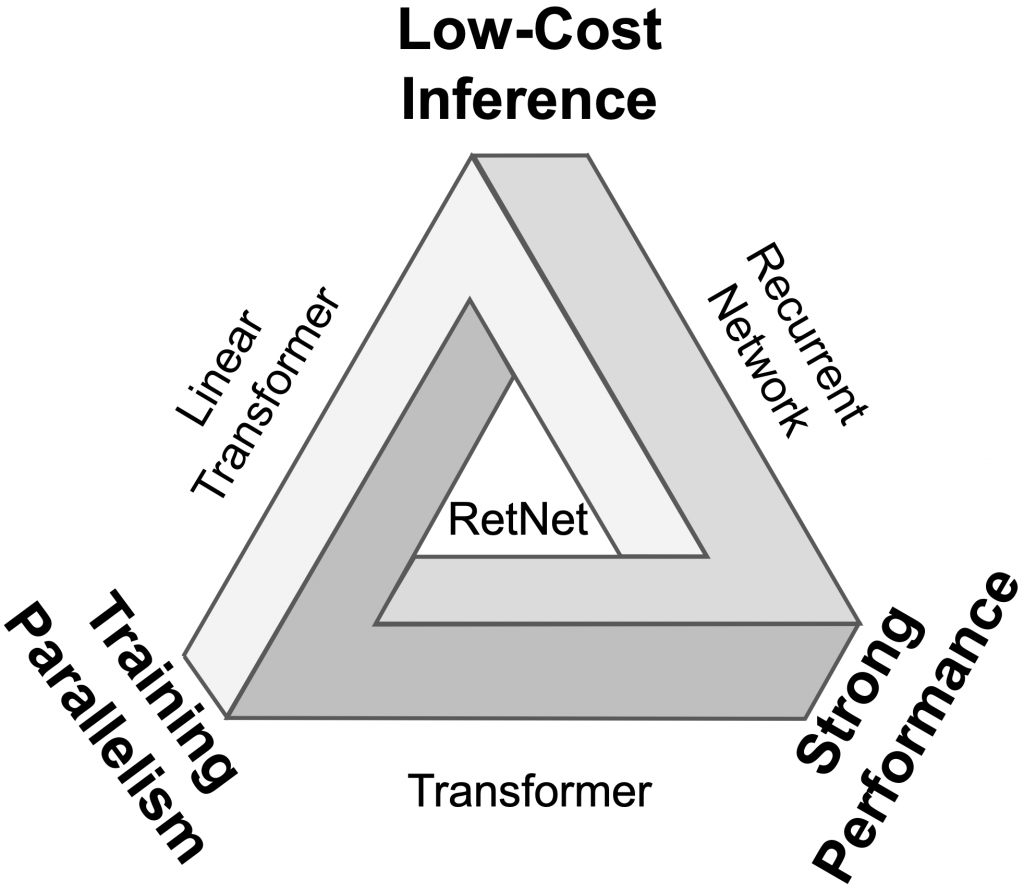
RetNet has been compared with previous methods and has demonstrated its advantages over other architectures. RetNet is a feasible solution to the “impossible triangle” depicted in Figure 1. RetNet outperforms other architectures in terms of scaling curves and in-context learning (see Figure 2). It also offers training parallelization, a constant inference cost, linear long-sequence memory complexity, and excellent performance.
When compared to Transformers, RetNet exhibits several clear advantages. In language modeling, RetNet achieves comparable results with Transformers and demonstrates favorable scaling behavior. In downstream tasks, RetNet performs at a similar level to Transformers for zero-shot and in-context learning. RetNet also exhibits advantages in training, being more memory-efficient and having higher throughput compared to Transformers. Similar advantages exist when comparing inference performance. The recurrent representation used by RetNet leads to reduced memory consumption, higher throughput, and consistent latency, which results in reduced inference cost compared to Transformers. The comparison with other efficient Transformer variants shows that RetNet achieves lower perplexity on both in-domain and out-of-domain evaluation datasets. Overall, the combination of improved performance and efficient training and inference makes RetNet a strong successor candidate to Transformers for large language models.
In conclusion, Retentive Networks have emerged as a breakthrough architecture for sequence modeling. They offer unmatched advantages in training parallelism, inference efficiency, and performance. Its efficient computation paradigms make it a promising successor candidate to Transformers for biotech applications, with the potential to revolutionize AI in biotechnological advancements. So, are we ready to dismiss Transformers and date the RetNet? Too early, to go steady, but we definitely will keep our eye on it!
Get in touch if you want to explore how powerful new AI models and our digital lab platform can transform your organization.


