 >
> Infinite Attention: Scaling Language Models for Extremely Long Context Understanding
We often deal with vast amounts of text-based data – from scientific literature and clinical trial reports to regulatory documentation and more. Being able to comprehend and synthesize information across these lengthy documents is crucial for driving research, making informed decisions, and ensuring compliance. However, traditional natural language processing (NLP) models like GPT-3 are limited in their ability to handle extremely long context due to computational constraints.
A recent breakthrough from Google AI1 introduces a novel technique called “Infini-attention” that enables large language models (LLMs) to scale to infinitely long contexts with bounded memory and compute. This game-changing approach has immense potential for the biotech industry, allowing us to fully leverage the latest AI for tackling complex, document-heavy challenges.
The Core Innovation: Infini-Attention
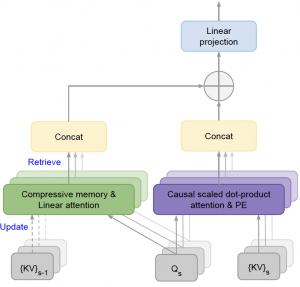
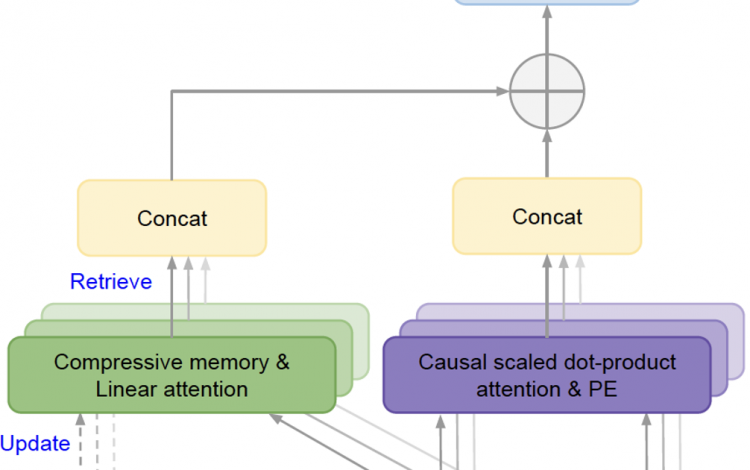
At the heart of this advancement lies the Infini-attention mechanism, which integrates a compressive memory module into the standard Transformer attention architecture used by most modern LLMs. Unlike the typical attention mechanism whose memory footprint grows quadratically with sequence length, Infini-attention maintains a fixed set of parameters to store and retrieve information efficiently.
This is achieved by augmenting the local causal attention with a long-term linear attention mechanism that continually updates a compressed representation of the entire context history. Notably, Infini-attention reuses the key, value, and query states computed during standard attention for memory consolidation and retrieval, introducing minimal additional parameters.
The result is a unified architecture that can stream over infinitely long inputs by “remembering” and incorporating relevant information from arbitrary context lengths during inference. This bounded memory approach is not only more scalable but also computationally efficient compared to retrieval or re-computation based methods.
Leveraging Infini-LLMs in Biotech
The remarkable context scaling enabled by Infini-attention unlocks transformative possibilities across various biotech domains:
Literature Understanding & Knowledge Synthesis
With Infini-LLMs, researchers can now truly leverage the wealth of scientific literature by comprehending full-text articles, book chapters, or even entire books in their raw form during training or inference. This empowers the models to connect insights scattered across lengthy documents, accelerating knowledge synthesis and discovery.
Clinical Trial Analysis
Comprehending the extensive documentation involved in clinical trials is a daunting task. Infini-LLMs can ingest and reason over complete trial protocols, patient data, safety reports, and regulatory guidelines, identifying critical insights that may be missed when analyzing these texts in isolation.
Regulatory Compliance
Ensuring adherence to complex, evolving regulations is a perpetual challenge. With their long context capabilities, Infini-LLMs can directly interpret rules, guidelines, and policies across different jurisdictions, providing a unified view to help biotech companies navigate the intricate regulatory landscape more effectively.
Drug Discovery & Development
The drug development lifecycle involves countless documents – from early-stage research papers and patents to manufacturing procedures and post-marketing surveillance data. Infini-LLMs can holistically understand and connect information throughout this extensive paper trail, potentially uncovering new opportunities or identifying risks faster.
Furthermore, the “plug-and-play” nature of Infini-attention allows existing LLMs to be efficiently adapted for long context processing via continual pre-training on relevant corpora.
Early Biotech Applications
Google’s team has already demonstrated the real-world efficacy of their Infini-Transformer models on tasks highly relevant to biotech:
- A 1 billion parameter model solved a passkey retrieval task involving 1 million token contexts after fine-tuning on only 5,000 token instances.
- An 8 billion parameter Infini-LLM achieved new state-of-the-art results on a 500,000 token book summarization benchmark by processing entire book texts.
These initial results showcase the remarkable context generalization capabilities of Infini-attention, opening up exciting opportunities for advancing biotech AI.
The Infini-attention approach represents a paradigm shift in how we leverage large language models, enabling us to tackle increasingly complex, document-centric challenges that were previously intractable. By strategically investing in and adopting these extremely long context AI models, biotech organizations can gain a significant competitive advantage – whether it’s accelerating drug development pipelines, optimizing regulatory strategies, or simply elevating their knowledge synthesis and decision-making capabilities.
The future of biotech innovation lies in our ability to truly understand and interconnect knowledge across vast realms of text-based data.
Sources:
1. Munkhdalai, T., Faruqui, M. & Gopal, S. Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention. arXiv preprint arXiv:2404.07143 (2024).


